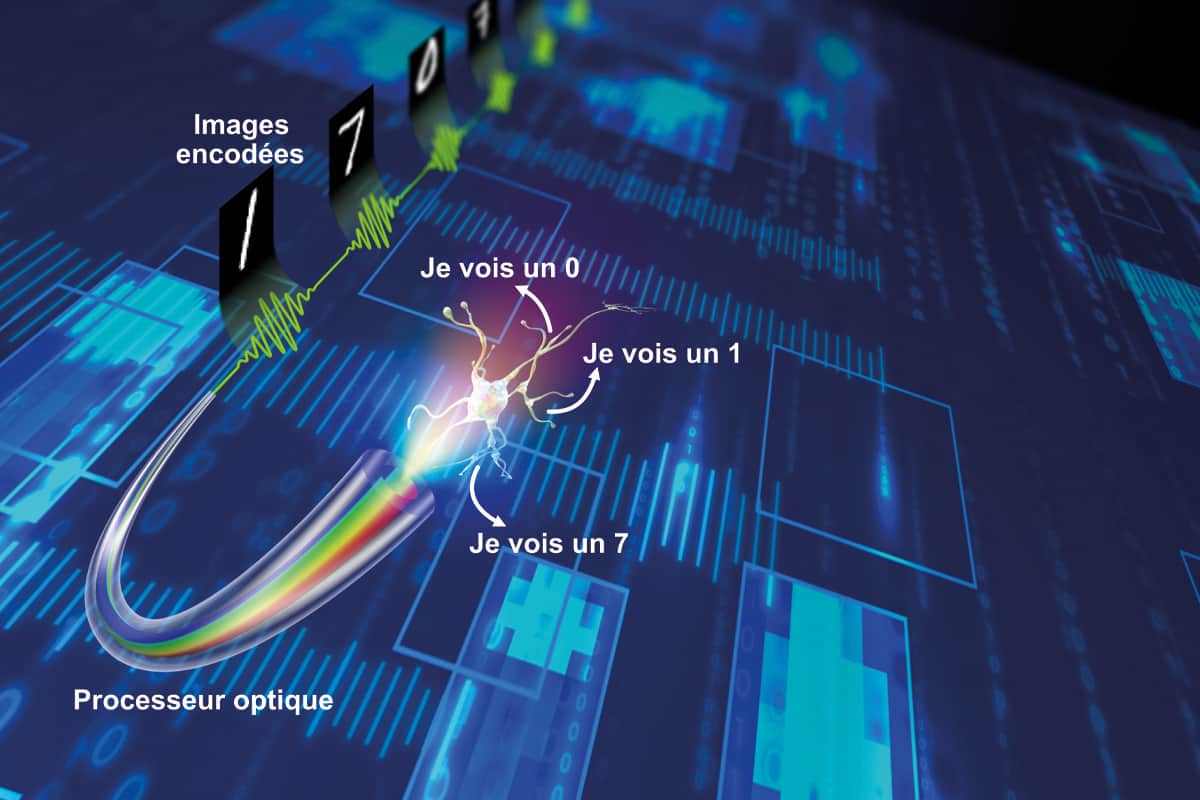
Une série d’images encodées dans des impulsions optiques, en vert, est identifiée grâce aux fréquences générées dans le processeur neuronal optique. Image:
L’apprentissage automatique pourra se faire plus rapidement, et à un coût énergétique bien moindre, grâce à un procédé entièrement optique.
Des programmes qui composent des poèmes sur demande, apprennent à reconnaître des chats, jouent au jeu de go… Les prouesses récentes de l’intelligence artificielle, propulsées par l’apprentissage automatique, sont stupéfiantes.
Cet apprentissage automatique, même s’il s’inspire des interactions entre les neurones dans notre cerveau, fonctionne en fait sur l’architecture classique des ordinateurs : des composantes électroniques où l’information est encodée de manière numérique (des 0 et des 1) et traitée dans des « portes logiques », après quoi chaque résultat est stocké dans des registres de mémoire temporaires.
Mais ces tâches exigent de nombreux allers-retours entre les unités de traitement et les registres de mémoire, avec un coût énergétique inouï : l’entraînement de ChatGPT-4, par exemple, a exigé quelque 50 GWh d’énergie, ce qui représente près de 2,5% de l’électricité produite par Hydro-Québec en 2022.
Lueur d’espoir
Afin de créer des systèmes à faible consommation d’énergie, plusieurs approches basées sur des composantes optiques ont vu le jour, capables de mener plusieurs opérations en parallèle sans avoir besoin de méga-infrastructure électronique. Une de ces techniques repose sur une particularité des fibres optiques : lorsque des impulsions lumineuses s’y propagent, elles sont modifiées à cause d’interactions entre la lumière et la fibre.